The record industry has filed a list of thousands of songs it believes have been scraped without permission, and has recreated versions of famous songs using Udio and Suno.
I have really mixed feelings about this. My stance is that I don’t you should need permission to train on somebody else’s work since that is far too restrictive on what people can do with the music (or anything else) they paid for. This assumes it was obtained fairly: buying the tracks of iTunes or similar and not torrenting them or dumping the library from a streaming service. Of course, this can change if a song it taken down from stores (you can’t buy it) or the price is so high that a normal person buying a small amount of songs could not afford them (say 50 USD a track). Same goes for non-commercial remixing and distribution. This is why I thinking judging these models and services on output is fairer: as long as you don’t reproduce the work you trained on I think that should be fine. Now this needs some exceptions: producing a summary, parody, heavily-changed version/sample (of these, I think this is the only one that is not protected already despite widespread use in music already).
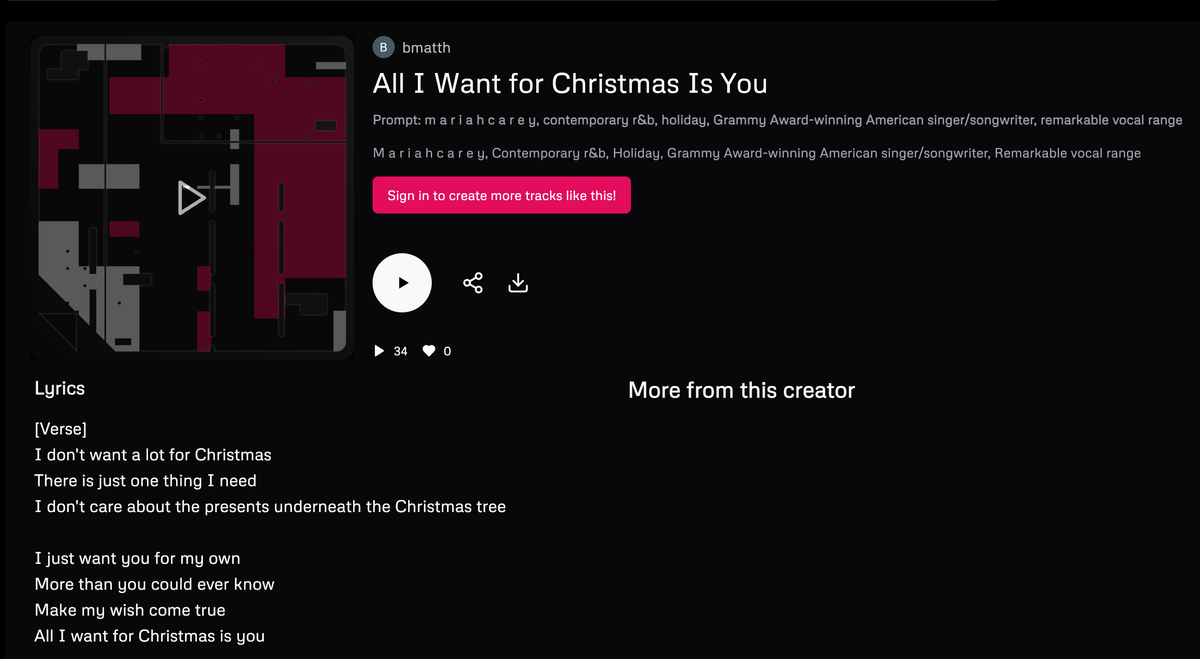
So putting this all together: the AIs mentioned seem to have re-produced partial copies of some of their training data, but it required fairly tortured prompts (I think some even provided lyrics in the prompt to get there) to do so since there are protections in place to prevent 1:1 reproductions; in my experience Suno rejects requests that involve artist names and one of the examples puts spaces between the letters of “Mariah”. But the AIs did do it. I’m not sure what to do with this. There have been lawsuits over samples and melodies so this is at least even handed Human vs AI wise. I’ve seen some pretty egregious copies of melodies too outside remixed and bootlegs to so these protections aren’t useless. I don’t know if maybe more work can be done to essentially Content ID AI output first to try and reduce this in the future? That said, if you wanted to just avoid paying for a song there are much easier ways to do it than getting a commercial AI service to make a poor quality replica. The lawsuit has some merit in that the AI produced replicas it shouldn’t have, but much of this wreaks of the kind of overreach that drives people to torrents in the first place.
My take is that you can train AI on whatever you want for research purposes, but if you brazenly distribute models trained on other people’s content, you should be liable for theft, especially if you are profiting off of it.
Just because AI has so much potential doesn’t mean we should be reckless and abusive with it. Just because we can build a plagiarism machine capable of reproducing facsimiles of humanity doesn’t mean that how we are building that is ethical or legal.
Copyright infringement becomes theft when you make money off of someone else’s work, which is the goal of every one of these AI companies. I 100% mean theft.


I have really mixed feelings about this. My stance is that I don’t you should need permission to train on somebody else’s work since that is far too restrictive on what people can do with the music (or anything else) they paid for. This assumes it was obtained fairly: buying the tracks of iTunes or similar and not torrenting them or dumping the library from a streaming service. Of course, this can change if a song it taken down from stores (you can’t buy it) or the price is so high that a normal person buying a small amount of songs could not afford them (say 50 USD a track). Same goes for non-commercial remixing and distribution. This is why I thinking judging these models and services on output is fairer: as long as you don’t reproduce the work you trained on I think that should be fine. Now this needs some exceptions: producing a summary, parody, heavily-changed version/sample (of these, I think this is the only one that is not protected already despite widespread use in music already).
So putting this all together: the AIs mentioned seem to have re-produced partial copies of some of their training data, but it required fairly tortured prompts (I think some even provided lyrics in the prompt to get there) to do so since there are protections in place to prevent 1:1 reproductions; in my experience Suno rejects requests that involve artist names and one of the examples puts spaces between the letters of “Mariah”. But the AIs did do it. I’m not sure what to do with this. There have been lawsuits over samples and melodies so this is at least even handed Human vs AI wise. I’ve seen some pretty egregious copies of melodies too outside remixed and bootlegs to so these protections aren’t useless. I don’t know if maybe more work can be done to essentially Content ID AI output first to try and reduce this in the future? That said, if you wanted to just avoid paying for a song there are much easier ways to do it than getting a commercial AI service to make a poor quality replica. The lawsuit has some merit in that the AI produced replicas it shouldn’t have, but much of this wreaks of the kind of overreach that drives people to torrents in the first place.
My take is that you can train AI on whatever you want for research purposes, but if you brazenly distribute models trained on other people’s content, you should be liable for theft, especially if you are profiting off of it.
Just because AI has so much potential doesn’t mean we should be reckless and abusive with it. Just because we can build a plagiarism machine capable of reproducing facsimiles of humanity doesn’t mean that how we are building that is ethical or legal.
That’s not what theft is. I think you mean copyright infringement.
Copyright infringement becomes theft when you make money off of someone else’s work, which is the goal of every one of these AI companies. I 100% mean theft.
Can you link to a single case where someone has been charged with theft for making money off something they’ve copied?
Or are you using some definition of the word theft that’s different from the legal definition?